2019. 8. 22. 23:49ㆍTech :Deep Learning
"Machine Learning이란?"
주어진 데이터(이전 결과 혹은 경험과 같은 )에 기반하여 Program의 Performance를 향상시키는 방법론?기술?로 인공지능 기술 중 하나이다. 간단하게 "주어진 데이터를 가장 잘 설명할 수 있는 방법"을 찾는다고 하면 될 것 같다.
= 주어진 데이터 셋를 분석하여 컴퓨터 프로그램을 만드는 방법
주어진 데이터로 Programming하는 과정을 "학습"이라고하며, 이미 음성처리, 얼굴인식, Web-search, 번역, 추천 필터링, 스팸 필터링, 마켓팅, 게임까지도 많이 쓰이고 있는 기술이다.

간단하게 "주어진 데이터를 가장 잘 설명할 수 있는 방법"을 찾는다라는 것이 쉽게 설명하면, 아래와 같이 어떤 점들(=데이터) 이 주어졌을 때 "주어진 좌표를 가장 잘 설명하는 함수 y"를 찾는 것이다.

위 점들을 지나는 선(=함수)를 찾고자 할때, 간단하게 Machine Learning의 과정을 단계로 나눠서 설명할 수 있다.
STEP 1 ) Universal Approximator ( 허용된 오차 범위 내에서 어떤 함수도 흉내낼 수 있는 함수로 Neural Network, Deep Learning, Decision Tree, Random Forest 등이 있다 ) 를 먼저 정하게 되는데 입력된 파라미터 x들과, 함수를 결정하는데 사용되는 파라미터들을 이용하여 아래와 같이 표현할 수 있다.

STEP 2 ) f 가 주어진 데이터에 가장 잘 부합하도록 w를 조정한다. ( 이 w를 찾아내는 과정을 "학습한다"라고 한다. )
 |
 |
 |
STEP 3 ) 결정된 f를 이용하여 값을 예측한다.

이러한 단계를 거치는 것이 Machine Learning의 과정이라고 쉽게 이해할 수 있다.
그럼 Machine Learning으로 풀 문제는 어떤 것이 있는가.
- Classification 문제 ( 음성/얼굴/지문/이미지/DNA/추천알고리즘 등등 ) : 입력이 주어졌을 때 출력이 0 아니면 1과 같이 명확한 값(=Label)이 주어지는 경우로 가장 간단한 예로, 얼굴 Data가 주어졌을 때, 출입권한이 있는지 없는지의 문제
- Regression 문제 (Loan application analysis, Marketing, Stock market prediction) : (x,y)가 주어졌을 때 (x는 벡터, y는 real number 실수), x와 y의 관계를 찾아내서 x`가 주어졌을 때 그 결과를 대답해야한다.
- Clustering 문제 (Web-search, Document & information retrieval, Machine translation,,,) : Unlabeled Data가 주어졌을때 (Label이란 input에 대한 결과를 알고있는 경우 그 정답을 말한다), Data를 숨겨진 데이터 구조를 알아냄으로써 Grouping해서 새로운 input(test data)가 들어왔을때 어떤 group에 속하는지 알아내야하는 문제
- Dimension Reduction : Unlabeled Data가 주어졌을 때 Data의 손실을 최소화하면서 아래와 같이 Data의 Dimension을 줄이는 방법
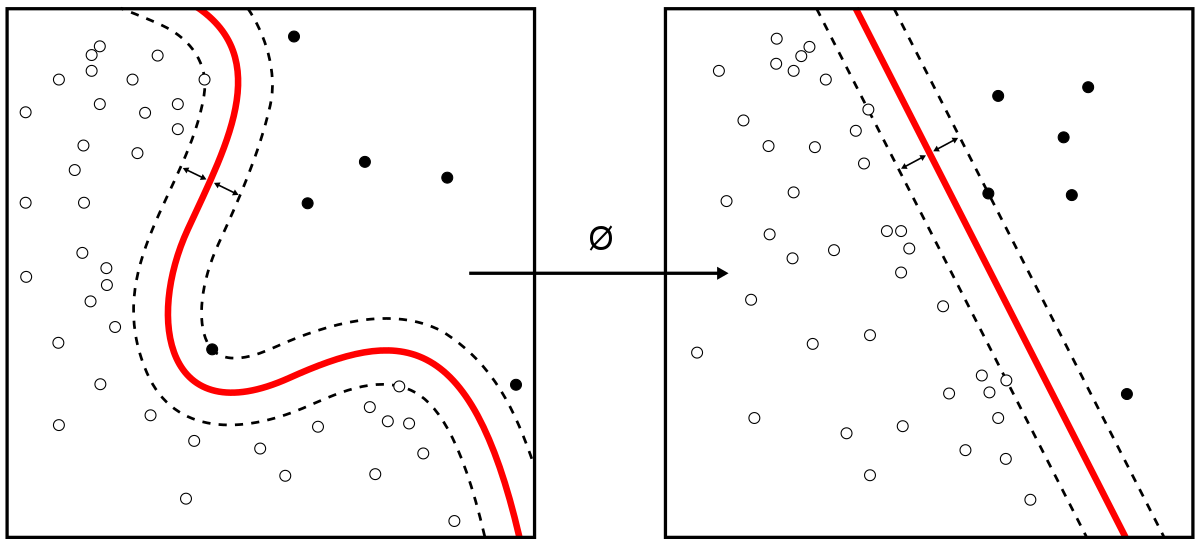
- Strategy Learning (Game, Marketing) : Game이 주어지면 어떻게 이기는지 모르지만 어떻게 이기는지 학습해서 이겨야하는 문제
- Association : items이 주어졌을 때 함께 나타나는 items을 찾는 문제 등등이 있다.

위 문제들을 푸는 Machine Learning의 방법은?
- Supervised Learning, Semi-supervised Learning, Unsupervised, Learning, Reinforment Learning, Parametric, Semiparametric, Nonparametric, None-meta Learning, Meta Learning 너무 여러가지 방법들이 있는데 그 관계도는 아래와로 쉽게? 표현된다.
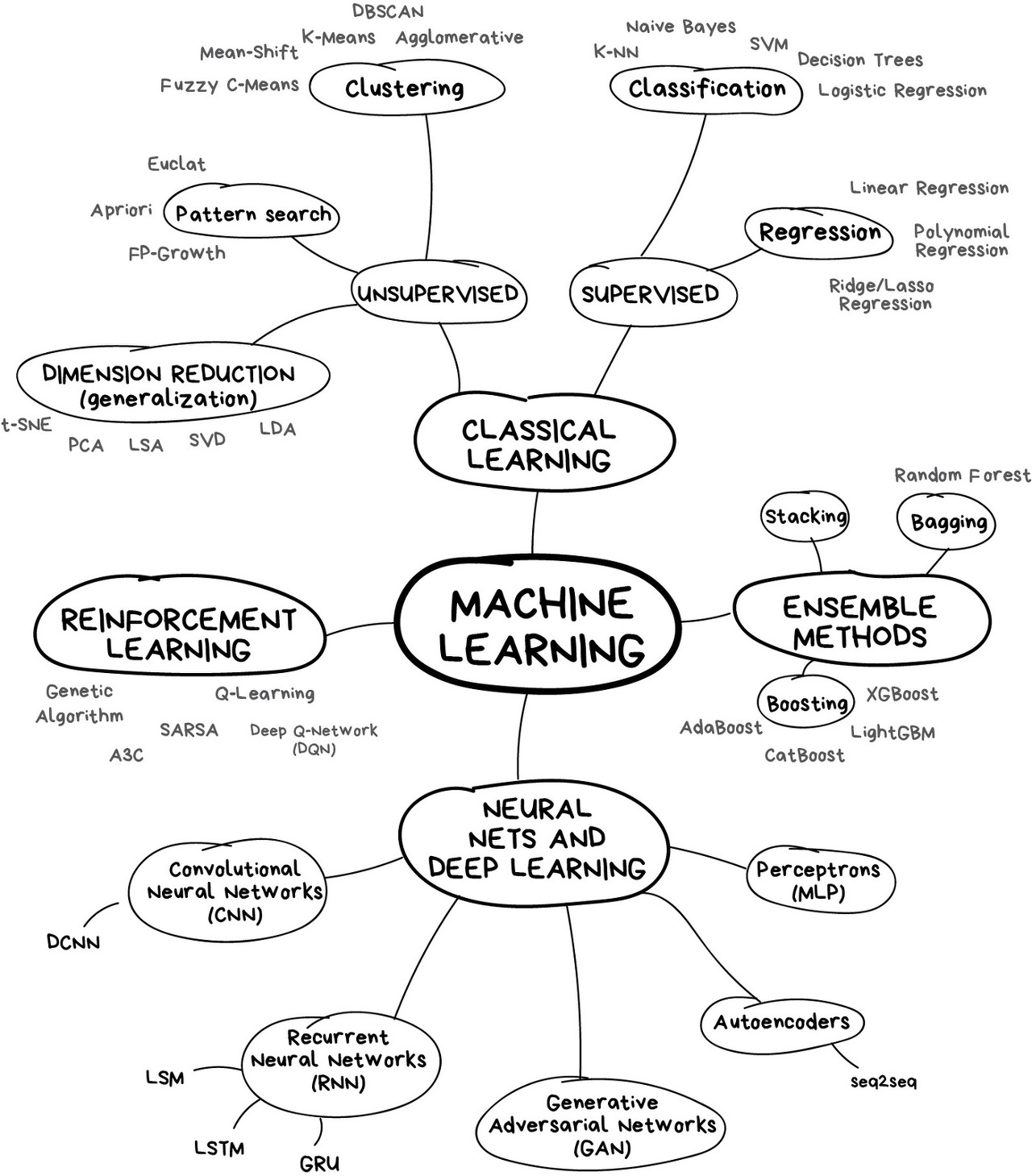
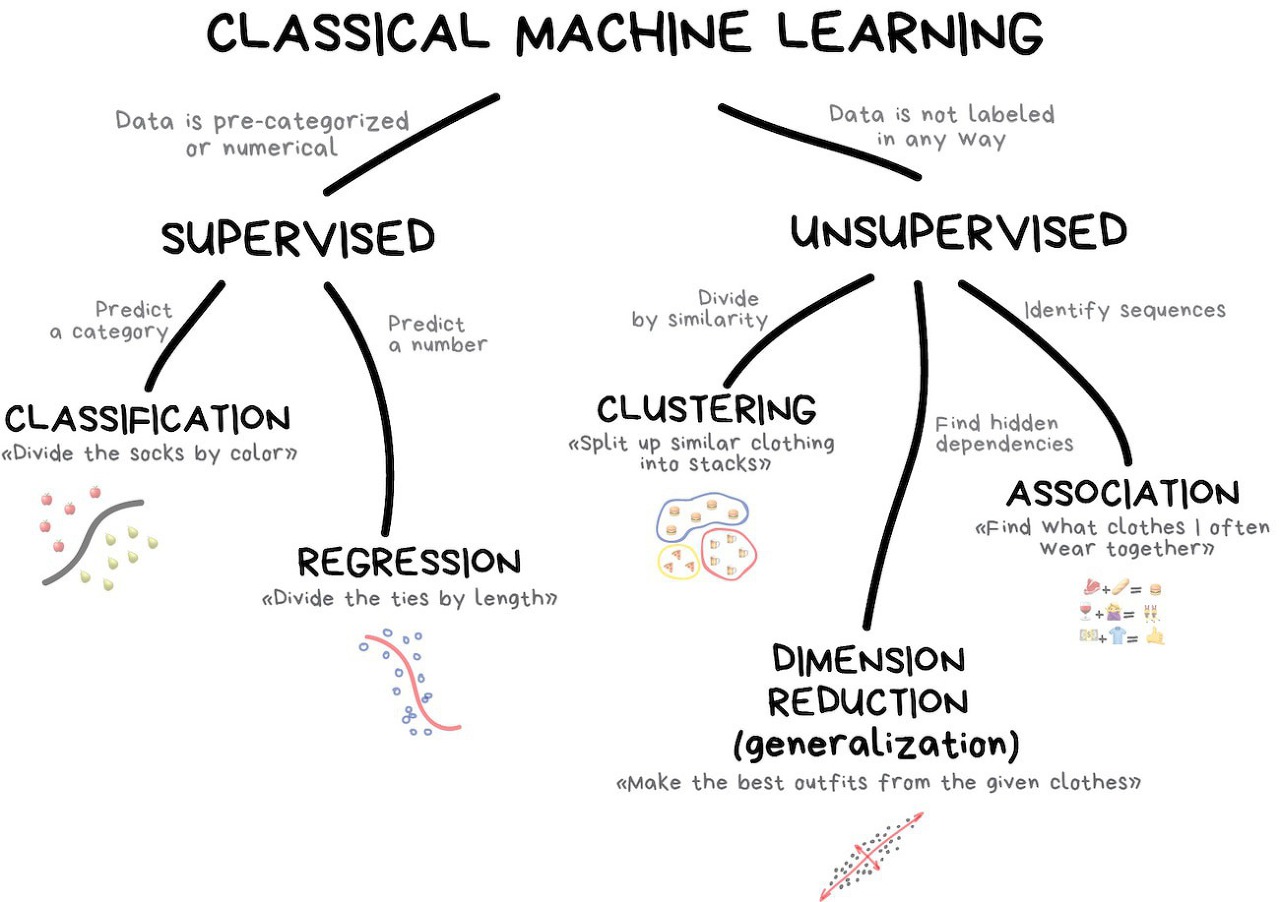
나는 아직 저 방법들 중 10%도 모르기 때문에,,, Classical Machine Learning 그림으로 다시 보면
Data의 정답을 미리 알고있으면 Supervised Learning, Data의 정답을 모르면 Unsupervised Learning이 되겠고,
Supervised Learning 방법으로 풀수있는 문제로는 0,1 과 같이 카테고리로 분류가 가능하면 Classification / 결과가 실수와 같은 형태로 나오면 Regression 과 같은 문제들이 있다.
Unsupervised Learning 방법으로 데이터를 유사도로 나누는 경우 Clustering, 연관성으로 나누는 경우 Association, 숨겨진 Dependency를 찾는 경우 Dimension Reduction이 문제들을 풀게 될 것 같다.
<Reference>
'Tech :Deep Learning' 카테고리의 다른 글
| 파이썬 딥러닝 - 05. EarlyStopping (0) | 2020.01.12 |
|---|---|
| 파이썬 딥러닝 - 04. 케라스 학습 과정 (0) | 2020.01.12 |
| 파이썬 딥러닝 - 02. 케라스 개발환경 구축 (0) | 2020.01.04 |
| 파이썬 딥러닝 - 01. 케라스 소개 (0) | 2020.01.04 |
| 02. 어떻게 Machine Learning을? (0) | 2019.09.01 |